
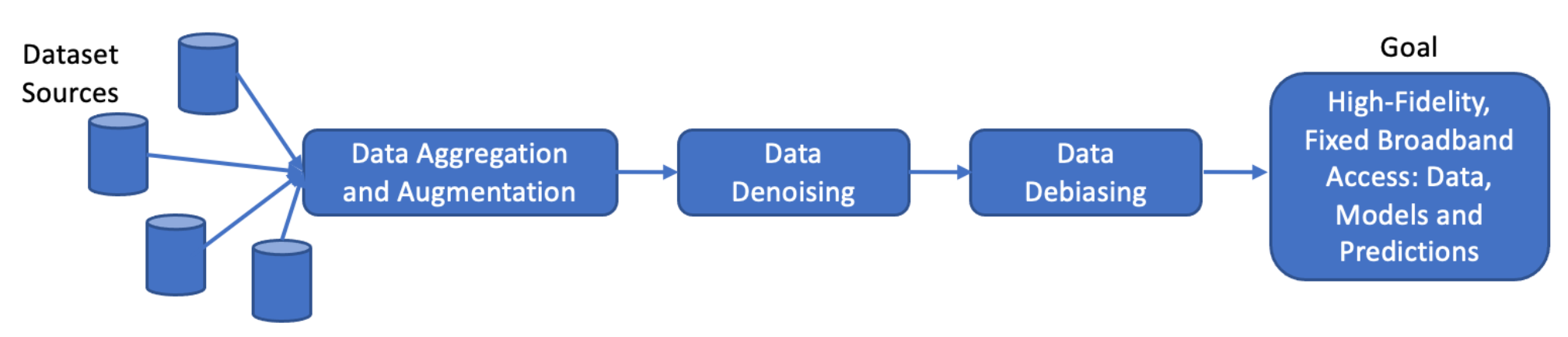
The ADDRESS project aims to Augment, Denoise and Debias crowdsourced measurements for statistical synthesis of Internet access characterization.
Project Overview
Internet Inequity in the US
The United States has long suffered from digital inequality that stretches in multiple dimensions. For instance, rural and tribal regions are far less likely than urban cities to have high quality, high-speed Internet access. Several demographic and socioeconomic factors, such as race, ethnicity, income, etc., are often indicators of Internet availability and quality.
Countering Internet Inequity
To fully bridge the Internet access divide and best allocate available funding, policymakers need to understand the state of Internet accessibility and quality. Further, they not only require accurate information on distributions of Internet quality in a geographical region, but also the contributors to the distribution’s tail (regions of poor quality).
In essence, policymakers need data that enables a complete characterization of Internet access quality at the most refined geographical granularity (i.e., street address level). The data should provide the following information:
- Where precisely the access does (not) exist,
- What broadband plans are available in a region, and
- Where precisely the networks do (not) meet the service goals.
Using Crowdsourced Speed Test Data to Aid Policy Decisions
To help provide this information, crowdsourced Internet measurement datasets, such as those collected by Measurement Lab (MLab), Ookla,and Measuring Broadband America (MBA), report actual Internet performance at the test locations.
However, these datasets have a variety of limitations. They are temporally and spatially sparse and unevenly distributed; they are noisy with respect to accurate identification of the actual path bottleneck; and they have biases along multiple dimensions, including across demographic and socioeconomic variables. This project aims to address these deficiencies through novel statistical techniques to augment, denoise, and debias crowdsourced Internet measurement datasets to provide the critical policy data discussed above.
Broadband-plan Querying Tool (BQT)
BQT is an outcome of the ADDRESS project. It is a tool that allows users to query the availability of broadband plans at a given address. It is currently in the development stage and has been tested to extract information from 8 ISPs. Our objective is to retrofit BQT with capabilities of querying more major, regional, and local ISPs in the future. We are working towards making BQT publicly available as soon as possible.
Overview
BQT utilizes advanced frameworks to simulate authentic user behavior and engages directly with various Internet Service Providers (ISPs) websites. Distributed across a range of geographical locations, this tool’s primary objective is to extract specific data about ISP-provided speeds and pricing at the granularity of street addresses. By curating a rich dataset spanning different types of locations (e.g. urban/rural) and demographics (e.g., low/high income) through this tool, it unlocks the potential to comprehend the affordability of ISP services deeply. This facet has remained largely inaccessible in the past due to a lack of appropriate datasets. This cutting-edge tool offers a unique and powerful approach to dispel the opacity around service provisioning, offering valuable insights for consumers, researchers, and policymakers alike.

How does BQT work?
We conduct thorough investigation of the specific components of an ISP’s website that a user must engage with when searching for broadband plans associated with a particular address. By doing so, we can pinpoint the website elements responsible for retrieving plan information based on the input of an address. Once the core website components are identified, we develop a BQT module using Python for the ISP. The module leverages Selenium, a popular web automation framework, to simulate user behavior and extract the desired information.
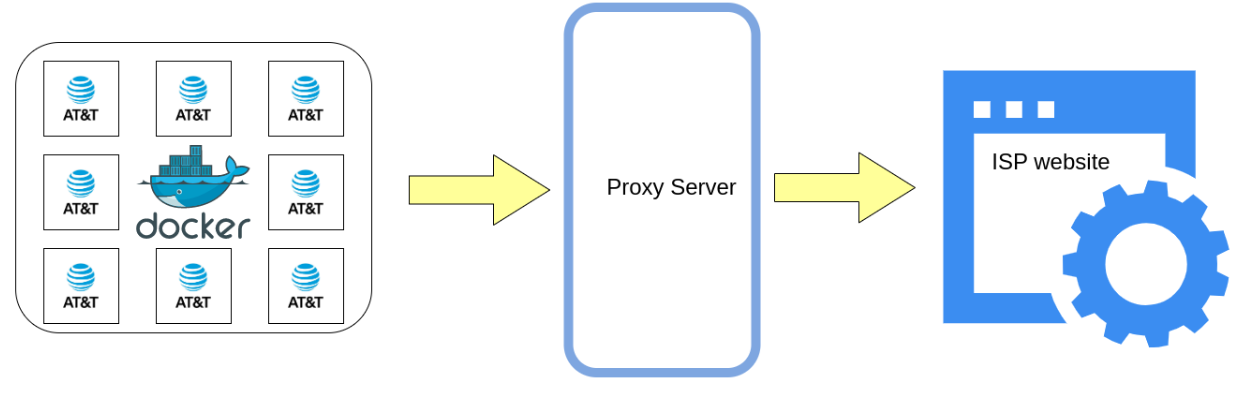
When it comes to efficiently querying multiple addresses for a given ISP, two significant challenges arise. Firstly, conducting multiple queries from a single IP address can result in the IP address being blocked due to potential restrictions or limitations imposed by the ISP. This can hinder the scalability of the querying process. Additionally, as we mimic organic user workflow (as opposed to scraping from the ISP backend which can be fast but unethical and brittle), the execution time can be slow when retrieving information for a single address, taking tens of seconds. Consequently, if a large number of addresses need to be queried, this extended execution time can accumulate and consume excessive amounts of time, impacting the overall scalability of the querying process.
-
To bypass the issue of querying using a single IP address, we partner with Bright Data, a leading proxy service provider. Through the Bright Initiative, the organization offers free access to data scraping tools for nonprofits and academic organizations. By using their services, we are able to pool of IP addresses that can be used to query multiple addresses without getting restricted by the ISP website.
-
To address the issue of slow execution time, we employ Docker containers and parallelize the querying process. For every ISP, we launch up to 100 Docker containers, each running with its own subset of addresses to query. This allows us to query 100 addresses simultaneously, thereby significantly reducing the overall execution time and enhancing the overall scalability. The figure below demonstrates the workflow for using Docker containers with the proxy to extract plan information from AT&T’s website.
One of the related research papers that leverages this tool won the Distinguished Paper Award (Long) at ACM SIGCOMM IMC 2022. The other research paper has been accepted for publication at ACM SIGCOMM 2023.
Acknowledgment
This effort is supported by:
- NSF Internet Measurement Research: Methodologies, Tools, and Infrastructure Grant, OAC-2220417
- NSF Rapid Response Research (RAPID) Grant, OAC-2033946
We are thankful to Bright Data for providing us free access to their IP proxy service. We extend our gratitude to Ookla and Zillow for sharing valuable datasets for this project.